Implementing Node.js URL parser in WebAssembly with Rust
Even though, this started as an experiment, implementing the URL parser in Rust using WebAssembly became the graduation project for my Masters in Computer Science at Fordham University.
A brief backstory
I’ve started my Master’s program on September 2021 and moved to New York from Istanbul, Turkey after working in the field for 10+ years. I’ve met with amazing people and professors in Fordham and took my graduation project at the end of my second semester (which is called Capstone project).
The goal of the Capstone Project is to give students and future engineers to work on a project with the pricinciples of Software Engineering to prepare them for the field. Since, I’ve had the field experience, I convinced my advisor, William Lord, to select a project which will make a significant contribution to one of my favorite runtime environments, Node.js.
Personal goal for graduation
My main goal for selecting my graduation project at Fordham were;
- The project should be technically challenging
- I need to learn and experience a new technology
- I need to give back to community. (If I’m going to spend more than 4 months on a project, I didn’t want it to go to waste)
- I want work on performance related stuff (which I didn’t had any chance in the past, due to my small startup experience)
The elevator pitch
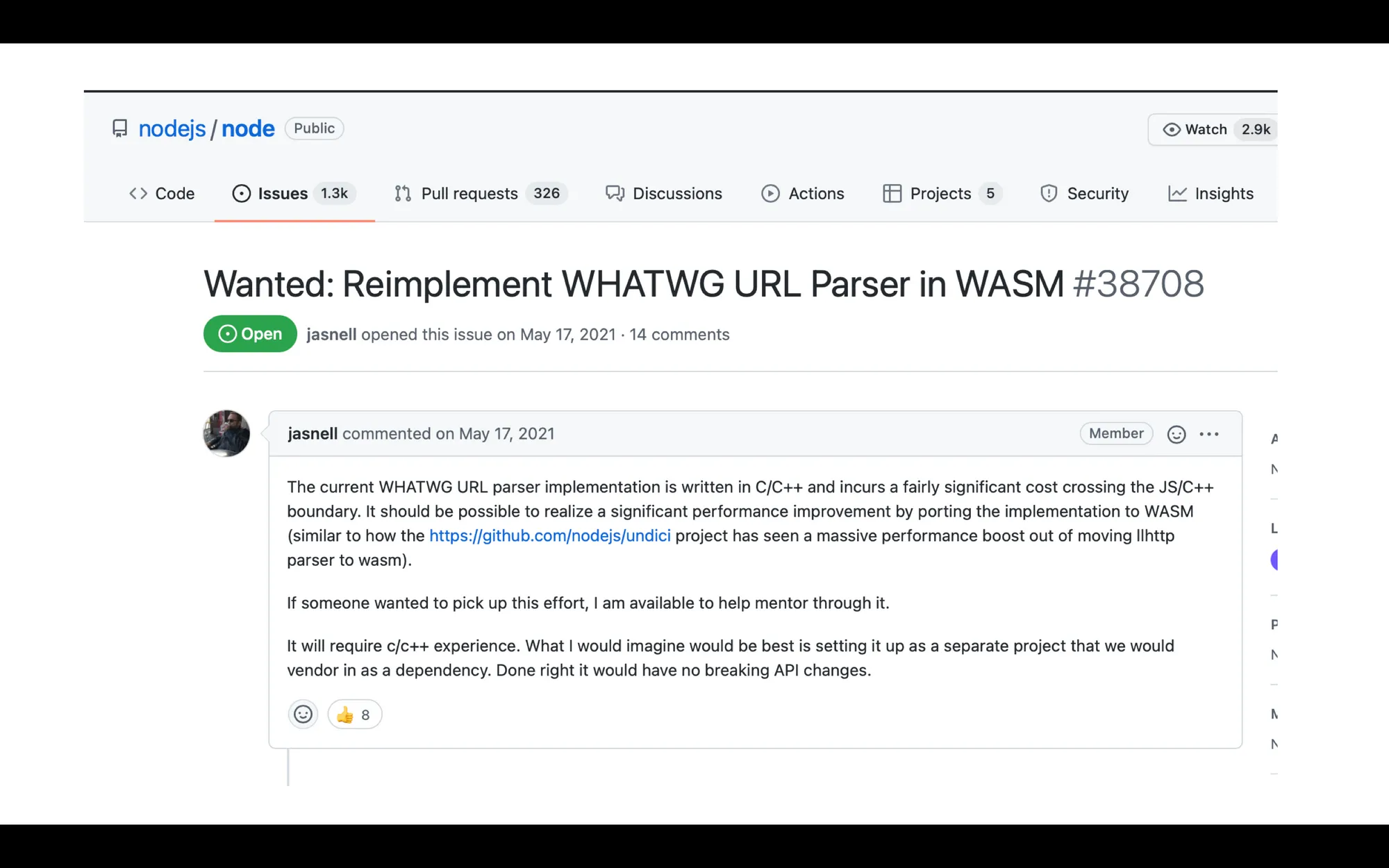
I saw an opportunity on the 48th page on Github issues on Node repository. There was a request for reimplementation for WHATWG URL Parser in WASM.
This was an important issue because it was mentioning:
- performance problems with C++ bridge and URL parser
- ”choose any technology you want” and compile into webassembly if it justifies the performance impact
- one of the most used functions in Node.js with a potential of changing a lot of things
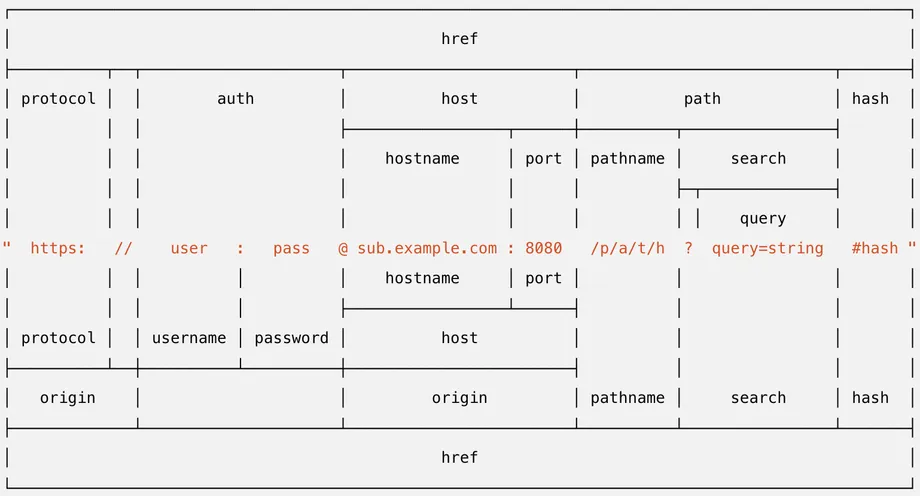
- being 100% API compliant with the existing implementation
So, here is my elevator pitch I’ve did to a bunch of students and teachers at Fordham University.




Beginnings
I’ve started reading the URL parser specification and understand the state machine behind it. Even though, I’ve implemented lots of state machines in the past, due to my selection of Rust (due to my eagerness to learn it), it was quite new for me to properly implement it using Rust.
I’ve created a repository and implemented an initial PoC with scheme parser support on the URL side and the complete URLSearchParams implementation.
Benchmarks
Before starting to implement the URL Parser state machine in Rust, I wanted to see how I am doing and what is the impact of the work I was going to create. I started using benchmarkify and added simple benchmark to test my code.
const {URL: RustURL, URLSearchParams: RustURLSearchParams} = require('url-wasm')
const Benchmarkify = require("benchmarkify");
const benchmark = new Benchmarkify("URL vs. Rust URL", {minSamples: 1000}).printHeader();
const index = benchmark.createSuite('URL')
index.add('URL', () => new URL('https://www.google.com/path/to/something'))
index.add('Rust::URL', () => new RustURL('https://www.google.com/path/to/something'))
const search_params_set = benchmark.createSuite('URLSearchParams.set')
search_params_set.add('URLSearchParams.set', () => {
let searchParams = new URLSearchParams('hello=world')
for (let i = 0; i < 100; i++) {
searchParams.set(`key-${i}`, `value-${i}`)
}
return searchParams.toString()
})The goal of the benchmark was to create a baseline before I did the serious stuff and see how it impacted through the releases I’ve did, and the progress I’ve made.
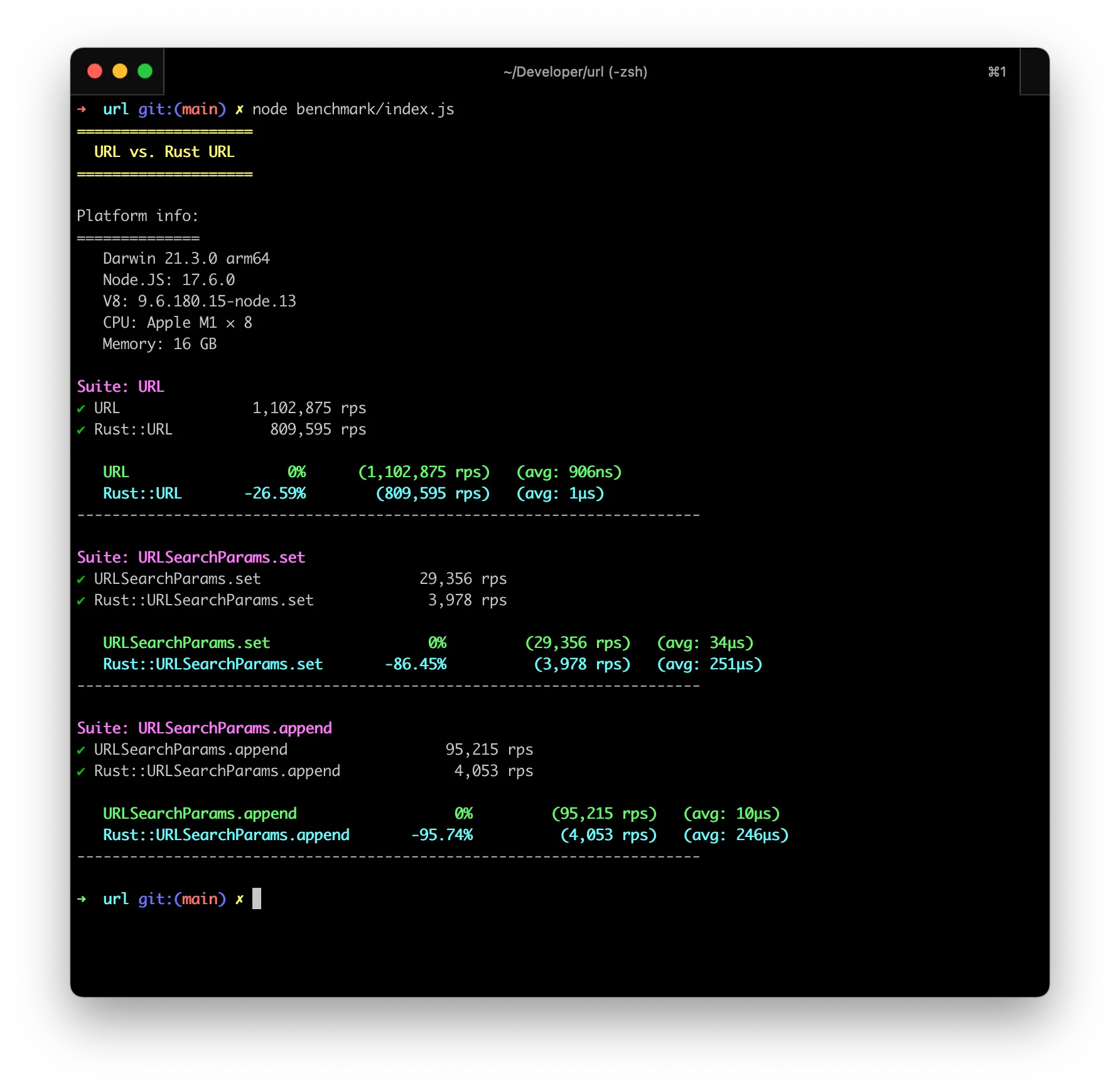
Shockingly, the benchmarks were really bad. My Rust URL implementation, which didn’t really do anything expect iterating through the input 1 time, was 27% slower than the actual implementation. Which was really shocking for me is that my URLSearchParams implementation was 86% adnd 95% slower for set and append functions, which basically just manipulated a vector inside Rust.
The results from my benchmarks were really bad, and it was alarming. I was doing something wrong.
Assumptions, assumptions, assumptions…
Here are my assumptions before diving into it.
- I was pretty sure I wasn’t using Rust in a performant way.
- My benchmarks were wrong, and v8 with JIT compiler was caching JavaScript in a much more performant way than WebAssembly
- I was questioning myself and thought I’ve missed a really important bullet point in the implementation.
- The javascript project auto-generated by
wasm-packwas not performant. (This assumption was based on my experience withauto-generatedlibraries and how a general approach is always slower than a implementation-specific approach)
Researching
1. I was pretty sure I wasn’t using Rust in a performant way.
Upon my research I’ve realized that there are 2 different flags where I can put into cargo.toml to compile the Rust code in a performant way. One of them was opt-level=3 which basically told the compiler to compile the code so that speed is preferred over space, and do it in the most agressive way. The second one was using lto = true. (LTO means Link-Time Optimization. It is generally set up to use the regular optimization passes used to produce object files)
After adding the 2 options, I saw 3-5% performance improvement compared to previous one. It was not enough.
2. My benchmarks were wrong, and v8 with JIT compiler was caching JavaScript in a much more performant way than WebAssembly
I’ve did some research and saw this amazing article . I’ve did some experimenting with the flags but did not see an major improvement compared to the previous benchmark that would reason with the performance regression.
This made me question if WebAssembly was the actual reason behind this issue. Upon researching and reading I’ve realized that UTF-16 to UTF-8 conversion between WebAssembly and Node.js using TextEncoder and TextDecoder was the primarily reason and the bottleneck.
3. I was questioning myself and thought I’ve missed a really important bullet point in the implementation.
The best way to know if you’re on the correct path was to actually ask for people’s help who have more experience on it than you. I’ve reached to Matteo Collina and James M. Snell from the Node.js Foundation Technical Steering Commitee.
Upon talking with James, he suggested I should try to reimplement the JavaScript layer without the help from wasm-pack and see what would be the change in terms of performance.
4. The javascript project auto-generated by wasm-pack was not performant.
I’ve started reimplementing the JavaScript layer and just benchmarked the initialization (passing the string from JavaScript to WebAssembly (Rust)).
class URL {
#ptr = null
constructor(url) {
if (url) {
const [ptr, vector_len] = passStringToWasm(url, instance.exports.__wbindgen_malloc, instance.exports.__wbindgen_realloc);
this.#ptr = instance.exports.url_new(ptr, vector_len)
}
}
}Benchmark results
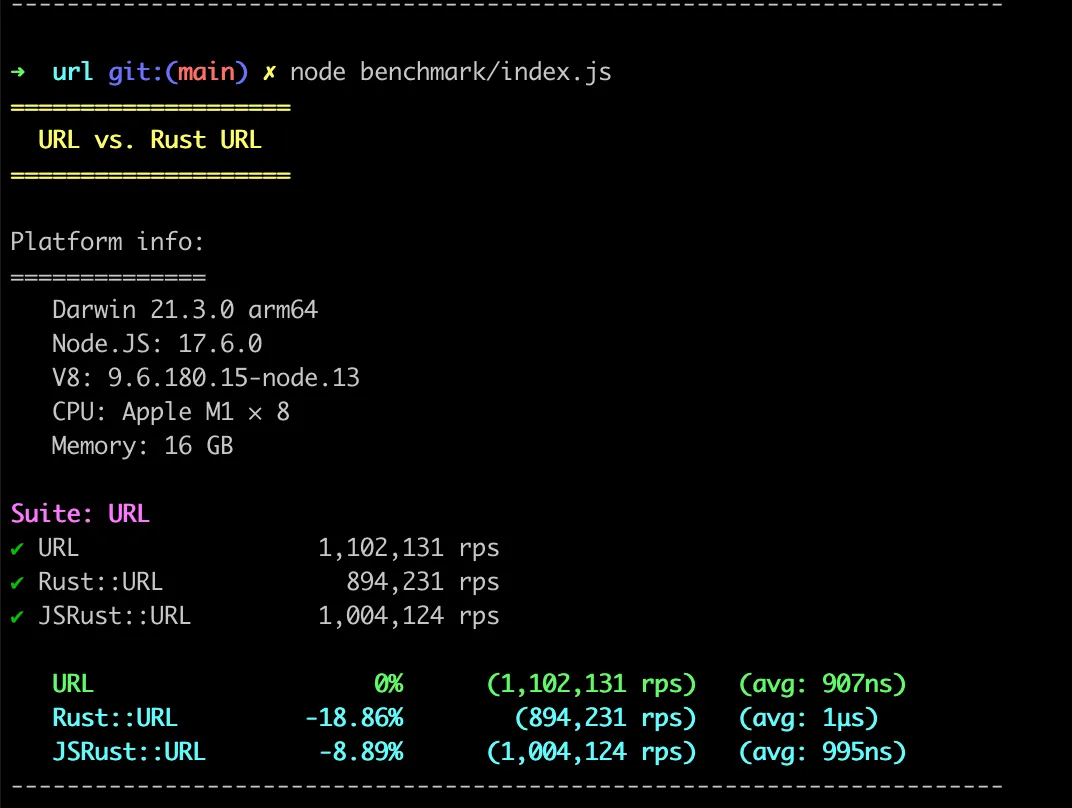
Upon implementing it and asking guidance from Matteo (due to his experience in working with Buffers), I’ve made the implementation faster. (18% compared to 8% performance degregation).
Conclusion
I’ve realized that even though WebAssembly is really performant for certain CPU/GPU intensive tasks, it was not the correct technology for small operations including high string encoding and decoding.
Companies such as 1Password prefer using WebAssembly over any other solution, is mainly because they’re using CPU/GPU intensive tasks focusing on cryptography and encryption where JavaScript and v8 does not have the capacity.
Even though this was an educational experience for me, I’ll implement the WHATWG URL parser in JavaScript and continue my effort to make it more performant than the existing solution using v8.
The Rust based implementation lives inside https://github.com/anonrig/url .